|
Is
Operant Behavior Facilitating Classical Conditioning at the Flight Simulator?
Björn Brembs, Reinhard Wolf and Martin Heisenberg
Theodor-Boveri-Institut für Biowissenschaften
(Biozentrum) Lehrstuhl für Genetik
Am Hubland, 97074 Würzburg
1. Introduction
While in recent years classical conditioning has been established as
an information transfer from the unconditioned to the conditioned stimulus,
the processes underlying operant conditioning are still poorly understood.
Modification of motor-programs in response to reinforcement accounts for
some but possibly not all cases.
The study of pattern learning in the Drosophila
flight simulator seems well suited to compare the two types of learning:
The same behavioral test - the choice between two patterns - can be
used to assess learning success in differently trained animals. During
training, the sequence of conditioned and unconditioned stimuli can
either be controlled by the fly itself (closed-loop, operant training)
or by the experimenter, the fly having no possibility to interfere (open-loop,
classical conditioning). In the flight simulator, the experimenter has
exquisite control over the various contingencies that one might establish
among behavioral output, visual input and the reinforcer.
The different processes assumed to underlie the different training
procedures might lead to different behavioral strategies to avoid the pattern
orientation associated with heat. For instance, if the classically trained
fly learned that one of the pattern orientations was associated with heat,
it might use the same behavioral repertoire to avoid this flight direction
as it employs to express a spontaneous pattern preference.
Conversely, during operant training flies may acquire a more effective
(or at least different) way to avoid the heat, selecting one of several
behavioral strategies. In this case, the motor-output should be different
from that of the naive and the classically conditioned flies.
The flight simulator provides the means for a detailed comparison of
the relationship between behavioral output, visual input and the reinforcer,
necessary to find behavioral optimizations.
2. Four Learning Paradigms
 Training:
Training:
operant conditioning:
The fly is enabled to control the appearance of the reinforcer (i.e. the
beam of infrared light) by its choice of flight direction with respect
to the angular positions of visual patterns at the arena wall ('closed
loop').
replay experiments:
The movements of the arena (together with the heating schedule), recorded
from a previously operantly trained fly, are played back to the fly ('open
loop').
static patterns:
In open loop, the panorama is kept stationary with
one pattern orientation in front of the fly. After 3s the panorama is quickly
rotated by 90°, thus bringing the other pattern orientation into the
frontal position. One of the two orientations is made contiguous with the
reinforcer.
rotating patterns:
The panorama is rotated continuously at w=30°/s in open loop. As the
heat is switched on/off every 90° (whenever the two pattern orientations
are at a 45° angle with respect to the longitudinal axis of the fly)
the same heating regime as during stationary pattern presentation is applied.
Test:
In all instances, the identical behavioral test is used to assess learning
success: The fly's pattern preference is measured in closed loop without
reinforcement.
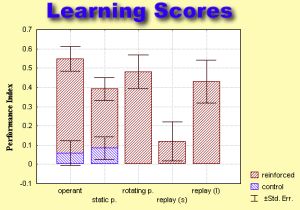 Average learning scores
of the four learning paradigms.
The preference index is calculated as (p2-pl)/(p2+pl), with p2 being the
time during which the pattern orientation not associated with heat was
kept in the frontal quadrant of the visual field and p1 denoting the remaining
time.
Average learning scores
of the four learning paradigms.
The preference index is calculated as (p2-pl)/(p2+pl), with p2 being the
time during which the pattern orientation not associated with heat was
kept in the frontal quadrant of the visual field and p1 denoting the remaining
time.
replay (s) - 2x4min replay-training
replay (l) - 4x4min replay training
3. Does the fly's behavior
during test reveal different avoidance strategies after the various conditioning
procedures ?
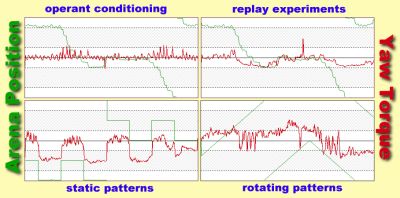
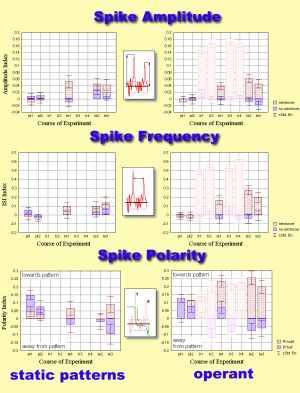
1. Yaw Torque:
Upon observing a fly in the flight simulator, it is striking that the fly
neither keeps the cylinder immobilized nor rotates it continuously: phases
of fairly straight flight are interrupted by sudden turns at high angular
velocity. The turns are due to short pulses of torque (torque spikes).
Results from previous studies suggest that the spikes are the primary behavior
by which the fly adjusts its orientation in the panorama. Therefore, spiking
behavior (e.g. spike amplitude, frequency, polarity,
etc.) seemes a suitable candidate to search for different behavioral strategies
acquired during conditioning.
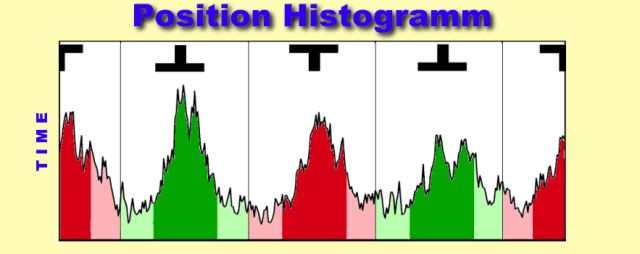
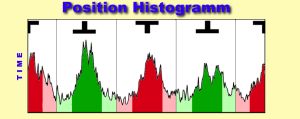
2. Arena Position:
The time the fly keeps the preferred pattern in the frontal position
is used to assess learning success. This information is stored in the position
trace. In contrast to the torque trace which only displayes the motor-output
of the fly, the position trace also contains information about the visual
input of the fly. Since the conditioned stimulus in all paradigms is visual
and in closed loop it is directly controlled by the fly, evaluation of
the position trace can yield important clues about different behavioral
strategies, aquired during training.
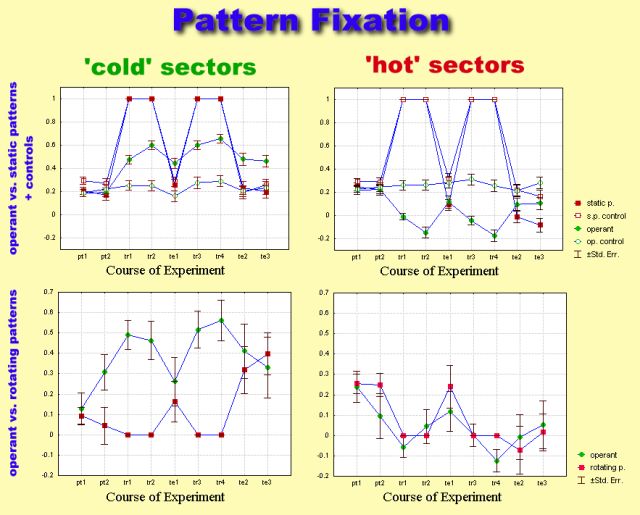
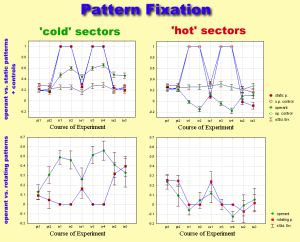
Since the only detectable difference in the torque trace was spike
polarity towards (away from) the pattern, the amount of time spent in the
vicinity of either patterns or sector borders was used to measure pattern
fixation.
4. Conclusion
"Under carefully controlled experimental
circumstances,
an animal will behave as it damned well pleases."
Harvard Law
of Animal Behavior
Comparison of flight behavior after operant training and after classical
conditioning with static patterns revealed only one parameter to be significantly
different: operantly trained flies chose flight directions as far away
from the heat-associated ones as possible (i.e. high pattern fixation).
Rotating the patterns during classical training instead of presenting them
stationarily abolished this difference. Apparently, the same avoidance
strategies are used after operant and classical conditioning. If
there are no differences, what is it that makes operant training more effective
than classical training?
Recording the sequence of conditioned and unconditioned stimuli during
2x4min of operant training and subsequently playing them back to a naive
fly, does not yield any significant learning scores. This shows that the
learning in the original experiment is indeed operant. Increasing the amount
of reinforcement by reiterating the replay training 4x4min, however, restores
learning scores to near control levels (see learning scores for short and
long replay-experiments). We thus propose that in the original experiment
operant behavior facilitates the information transfer from the unconditioned
to the conditioned stimulus, so that less reinforcement is required to
perform the same task.
© This poster was first published at the XXV. Göttingen Neurobiology conference.
You can also get this poster in PDF-format! |